
TL;DR
Partitioning splits a big table into smaller pieces on the same machine. Sharding spreads those pieces across multiple machines. I break down when to use each, when to combine them, and when sharding is more trouble than it is worth.
In this post, I’m going to break down the differences between database sharding vs. partitioning. Both are methods of breaking a large dataset into smaller subsets - but there are differences. This article explores when to use each - or even to combine them for data-intensive applications.
Database Sharding vs. Partitioning: What’s the Difference?
Introduction:
If you’ve spent time researching scalable database architecture techniques, chances are that you’ve run across the terms “sharding” and “partitioning.” So what is the difference between these two concepts? Now, at first glance, these two terms and concepts might seem rather similar. This is because sharding and partitioning are both related to breaking up a large data set into smaller subsets. The difference is that sharding implies the data is spread across multiple computers while partitioning does not. Let’s explore each concept in detail.
What is Partitioning?
Partitioning is the database process where very large tables are divided into multiple smaller parts. By splitting a large table into smaller, individual tables, queries that access only a fraction of the data can run faster because there is less data to scan. The main goal of partitioning is to aid in the maintenance of large tables and to reduce the overall response time to read and load data for particular SQL operations.
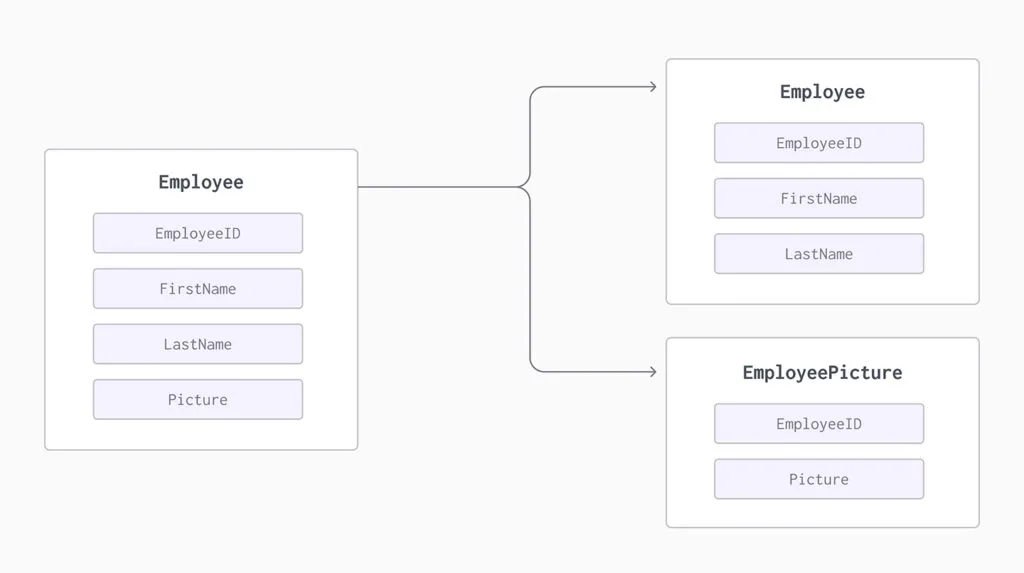
Vertical Partitioning
Vertical table partitioning is mostly used to increase SQL Server performance especially in cases where a query retrieves all columns from a table that contains a number of very wide text or BLOB columns. In this case to reduce access times the BLOB columns can be split into their own table. Another example is to restrict access to sensitive data e.g. passwords, salary information, etc. Vertical partitioning splits a table into two or more tables containing different columns:
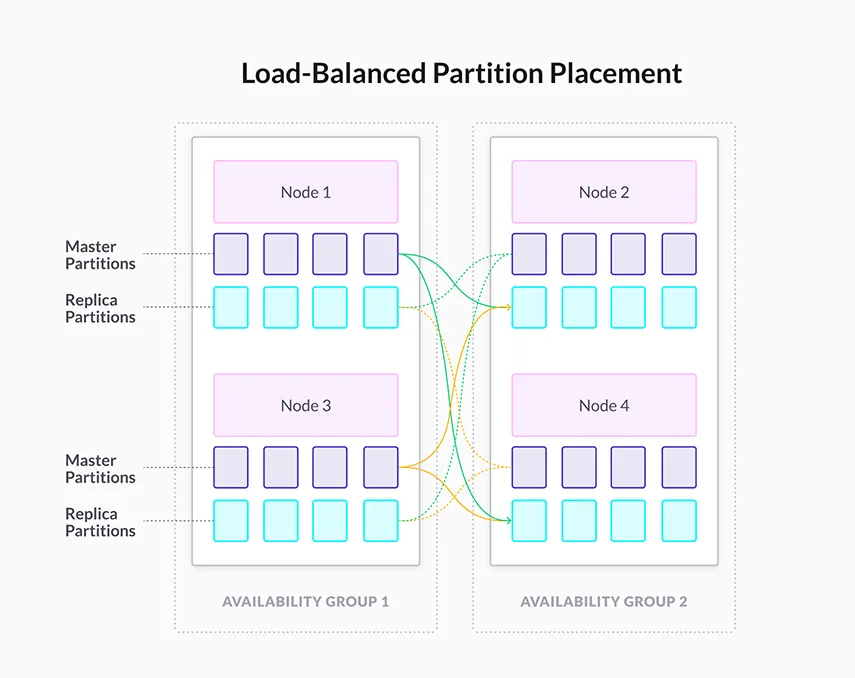
On SingleStore, by default, When you run CREATE DATABASE, SingleStore splits the database into partitions, which are distributed evenly among available nodes. This allows SingleStore to be highly available by default. With CREATE DATABASE, you can specify the number of partitions with the PARTITIONS=X option.
When to partition a table?
Here are some suggestions for when to partition a table:
-
Tables greater than 2 GB should always be considered as candidates for partitioning.
-
Tables containing historical data, in which new data is added into the newest partition. A typical example is a historical table where only the current month’s data is updatable and the other 11 months are read only.
-
When the contents of a table need to be distributed across different types of storage devices.
What is Sharding?
Sharding is actually a type of database partitioning, more specifically, Horizontal Partitioning. Sharding is replicating [copying] the schema, and then dividing the data based on a shard key onto a separate database server instance, to spread the load.
Every distributed table has exactly one shard key. A shard key can contain any number of columns. On SingleStore, when you run CREATE TABLE to create a table, you can specify a shard key for the table.
A table’s shard key determines in which partition a given row in the table is stored. When you run an INSERT query, the node computes a hash function of the values in the column or columns that make up the shard key, which produces the partition number where the row should be stored. The node then directs the INSERT operation to the appropriate node machine and partition.
For example, the table below has the shard key that contains only the first column. All people with the same first name will be stored on the same partition.
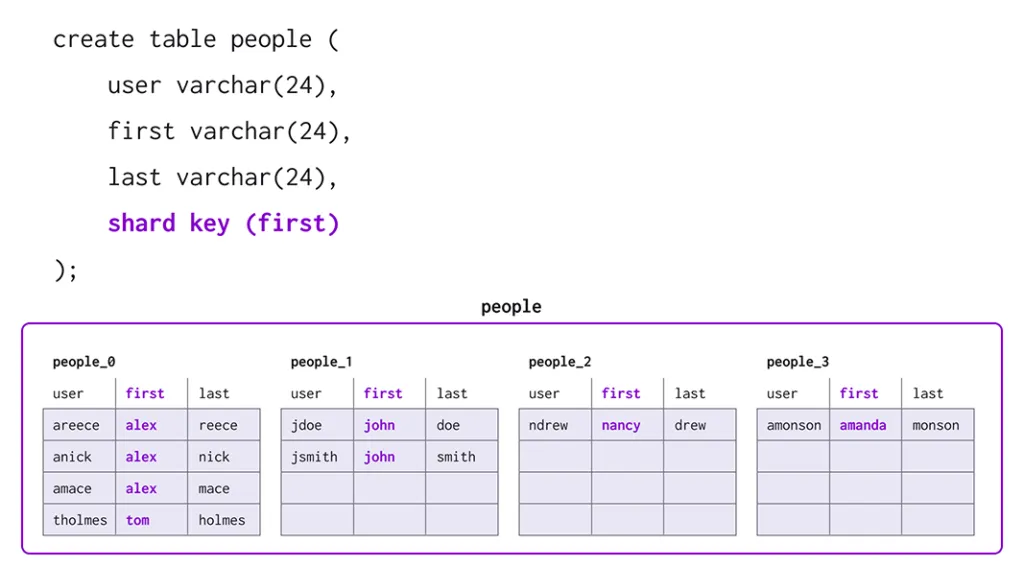
Note: See the Optimizing Table Data Structures guide for information on how to choose a shard key.
When to Shard a table?
Sharding your data can lead to many large performance improvements in your database. The following are some examples of how sharding can help improve performance:
-
Reduced index size – Since the tables are divided and distributed into multiple servers, the total number of rows in each table in each database is reduced. This reduces index size, which generally improves search performance.
-
Distribute database over multiple machines – A database shard can be placed on separate hardware, and multiple shards can be placed on multiple machines. This enables a distribution of the database over a large number of machines, greatly improving performance
-
Segment data by geography – In addition, if the database shard is based on some real-world segmentation of the data (e.g., European customers v. American customers) then it may be possible to infer the appropriate shard membership easily and automatically, and query only the relevant shard.
When NOT to shard a table?
Sharding should be used only when all other options for optimization are inadequate. The introduced complexity of database sharding causes the following potential problems:
-
SQL complexity – Increased bugs because the developers have to write more complicated SQL to handle sharding logic
-
Additional software – that partitions, balances, coordinates, and ensures integrity can fail
-
Single point of failure – Corruption of one shard due to network/hardware/systems problems causes failure of the entire table.
-
Fail-over server complexity – Fail-over servers must have copies of the fleets of database shards.
-
Backups complexity – Database backups of the individual shards must be coordinated with the backups of the other shards.
-
Operational complexity – Adding/removing indexes, adding/deleting columns, modifying the schema becomes much more difficult.
Luckily, SingleStore manages most of these added complexities from sharding your data for you, so you don’t have to worry!
Sharding vs. Partitioning: What’s the Difference?
Partitioning is a generic term that just means dividing your logical entities into different physical entities for performance, availability, or some other purpose. “Horizontal partitioning”, or sharding, is replicating the schema, and then dividing the data based on a shard key.
On a final note, you can combine both partitioning and sharding techniques on your database. Sometimes using both strategies is required for data-intensive applications. If you’re working with MongoDB specifically, I wrote about how to manage MongoDB data at scale using Atlas Online Archive, which is another useful tool for handling growing datasets.
So, now that we’ve discussed the difference between sharding and partitioning, what’s next? If you want to play around with sharding and partitioning techniques in the cloud, the best way is to spin up a database cluster on SingleStore and try it out for yourself! You can sign up for FREE here:
Sign up for a free SingleStore trial
Personally, I would also recommend that you check out the SingleStore Developers site. There are tons of great developer projects and demos for many languages, frameworks, and integrations.
The SingleStore Training page includes more self-paced courses like Schema Design, Data Ingestion, Optimizing Queries, and more.
If you run into any issues or get stuck, make sure to connect with the SingleStore community and get all of your questions answered, or check out more cool developer content on our SingleStore Developer page. The community forums are the best place to get your SingleStore questions answered.
Follow us on X to keep up on more cool dev stuff.