
Have you ever needed to make queries across databases, clusters, data centers, or even mix it with data stored in an AWS S3 blob? You probably haven’t had to do all of these at once, but I’m guessing you’ve needed to do at least one of these at some point in your career. I’ll also bet that you didn’t know that this is possible (and easy) to do with MongoDB federated queries on a MongoDB Atlas Data Lake! These allow you to configure multiple remote MongoDB deployments, and enable federated queries across all the configured deployments.

In this post, I will guide you through the process of how to query from multiple MongoDB Databases.
MongoDB Federated Query allows you to perform queries across many MongoDB systems, including Clusters, Databases, and even AWS S3 buckets. Here’s how MongoDB federated query works in practice.
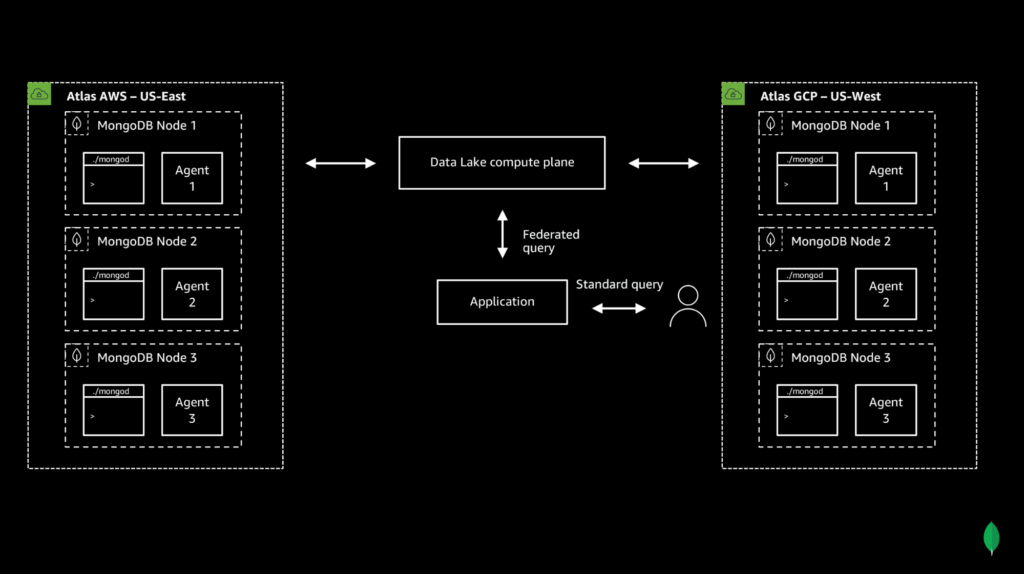
Note: In this post, we will be demoing how to query from two separate databases. However, if you want to query data from two separate collections that are in the same database, I would personally recommend that you use the $lookup (aggregation pipeline) query. $lookup performs a left outer join to an unsharded collection in the same database to filter documents from the “joined” collection for processing. In this scenario, using a data lake is not necessary.
tl;dr: In this post, I will guide you through the process of creating and connecting to a Data Lake in MongoDB Atlas, configuring paths to collections in two separate MongoDB databases stored in separate data centers, and querying data from both databases using only a single query.
Prerequisites
In order to follow along this tutorial, you need to:
- Create at least two M10 clusters in MongoDB Atlas. For this demo, I have created two databases deployed to separate Cloud Providers (AWS and GCP). Click here for information on setting up a new MongoDB Atlas cluster.
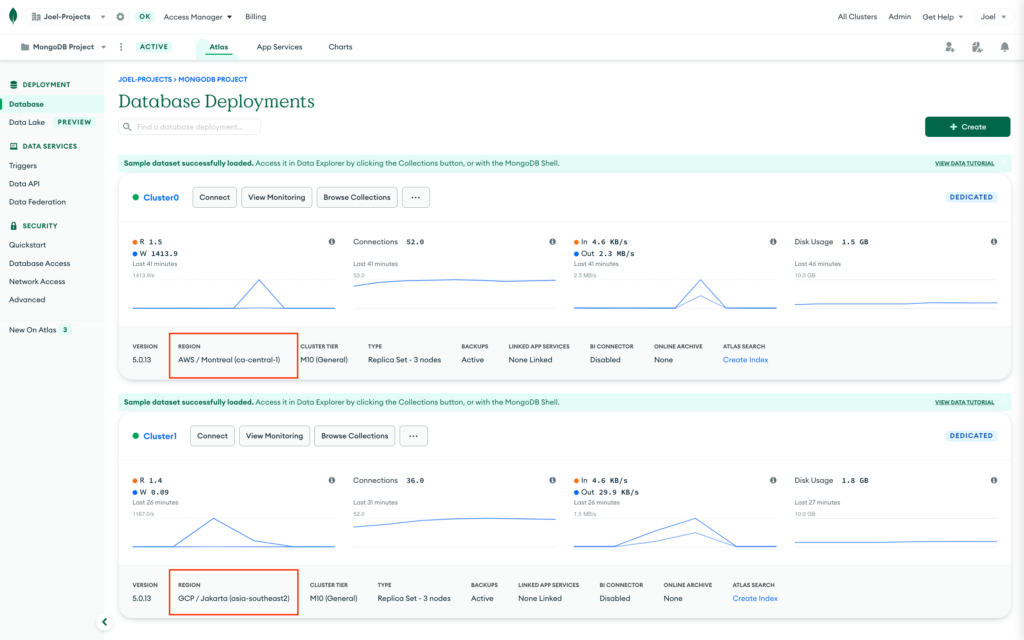
- Ensure that each database has been seeded by loading sample data into our Atlas cluster.
- Have a Mongo Shell installed.
Deploy a Data Lake
First, make sure you are logged into MongoDB Atlas. Next, select the Data Lake option on the left-hand navigation.
Create a Data Lake.
- For your first Data Lake, click Create a Data Lake.
- For your subsequent Data Lakes, click Configure a New Data Lake.

Click Connect Data on the Data Lake Configuration page, and select MongoDB Atlas Cluster. Select your first cluster, input sample_airbnb as the databases and listingsAndReviews as the collection. For this tutorial, we will be analyzing Airbnb rental data and some sample weather data to see if we can draw any insights into renting behaviors on Airbnb and the weather.
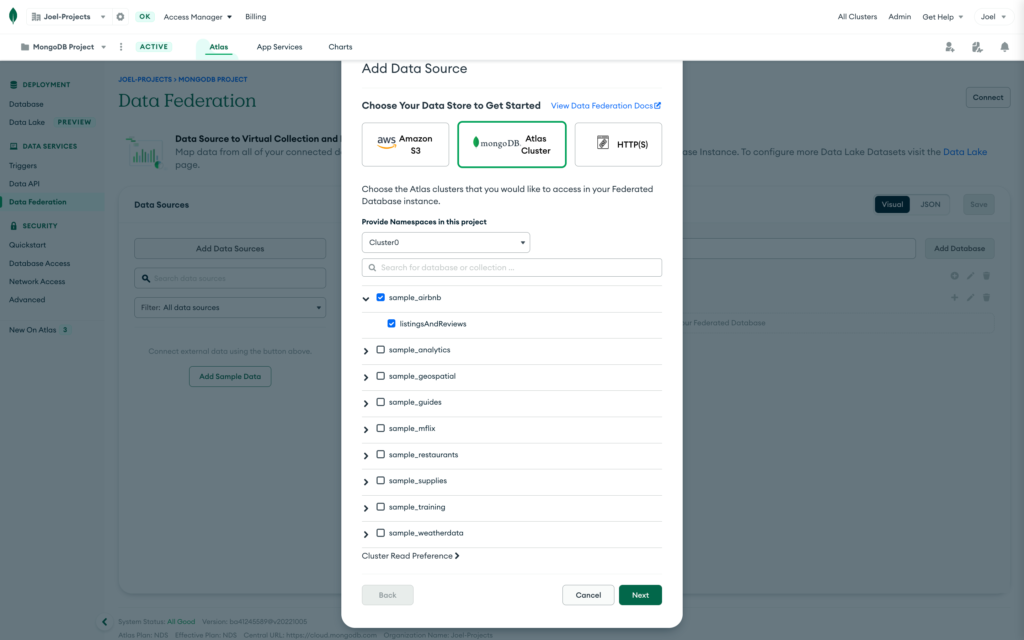
Repeat the steps above to connect the data for your other cluster and data source.
Next, drag these new data stores into your data lake and click save. It should look like this.
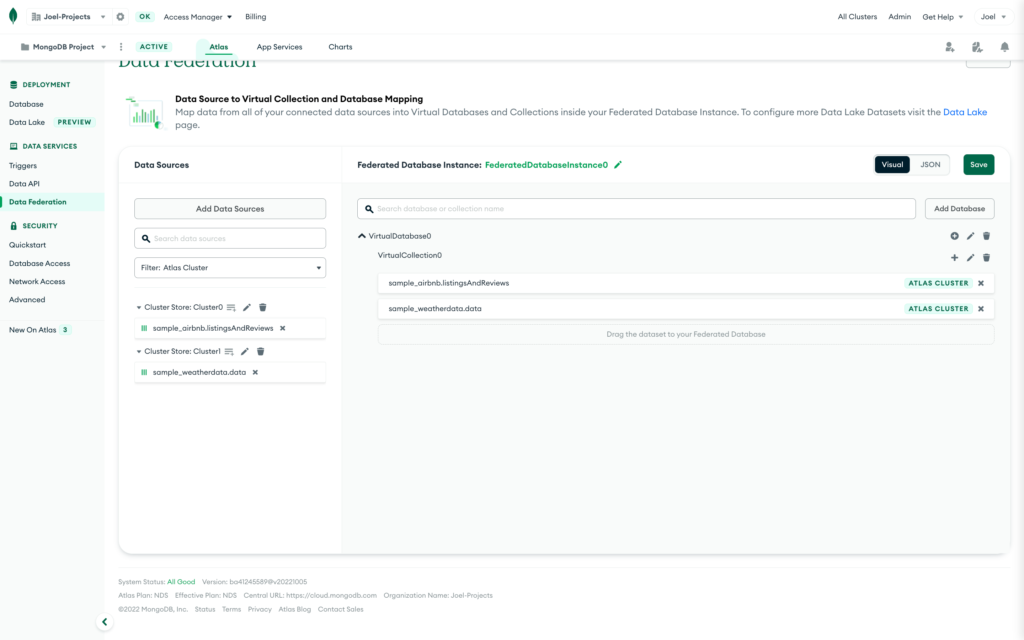
Connect to Your Data Lake
The next thing we are going to need to do after setting up our data lake is to connect to it so we can start running queries on all of our data. First, click connect in the second box on the data lake overview page.

Click Add Your Current IP Address. Enter your IP address and an optional description, then click Add IP Address. In the Create a MongoDB User step of the dialog, enter a Username and a Password for your database user. (Note: You’ll use this username and password combination to access data on your cluster.)
Query from Multiple MongoDB Databases
You can run your queries any way you feel comfortable. You can use MongoDB Compass, the MongoDB Shell, connect to an application or anything you see fit. For this demo, I’m going to be running my queries using MongoDB Visual Studio Code plugin and leveraging its Playgrounds feature. For more information on using this plugin, check out this post on our Developer Hub.
Make sure you are using the connection string for your data lake and not for your individual MongoDB databases. To get the connection string for your new data lake, click the connect button on the MongoDB Atlas Data Lake overview page. Then click on Connect using MongoDB Compass. Copy this connection string to your clipboard.
Note: You will need to add the password of the user that you authorized to access your data lake here.
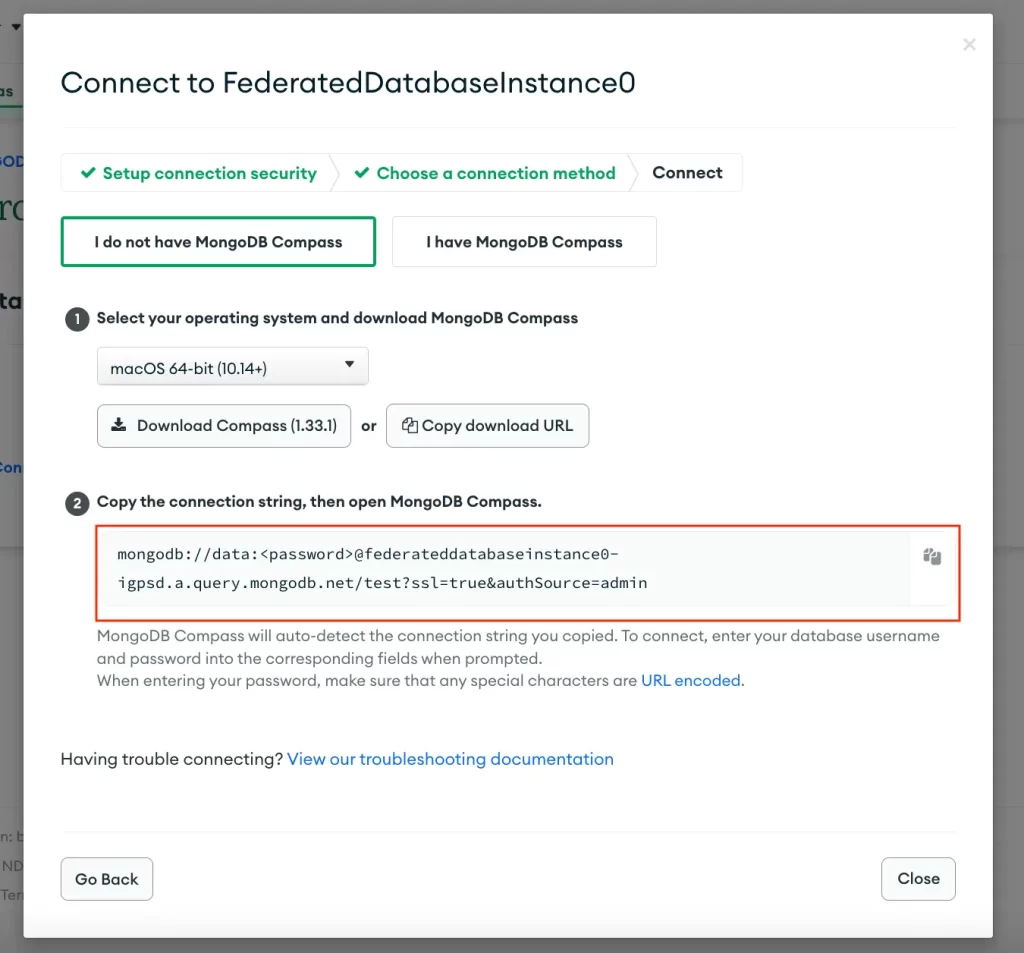
You’re going to paste this connection string into the MongoDB Visual Studio Code plugin when you add a new connection.
Note: If you need assistance with getting started with the MongoDB Visual Studio Code Plugin, be sure to check out my post, How To Use The MongoDB Visual Studio Code Plugin, and the official documentation.
You can run operations using the MongoDB Query Language (MQL) which includes most, but not all, standard server commands. To learn which MQL operations are supported, see the MQL Support documentation.
The following queries use the paths that you added to your Data Lake during deployment.
For this query, I wanted to construct a unique aggregation that could only be used if both sample datasets were combined using federated query and MongoDB Atlas Data Lake. For this example, I am running a query to determine the number of theaters and restaurants in each zip code, by analyzing the sample_restaurants.restaurants and the sample_mflix.theaters datasets. If you haven’t added these data sources to your data lake, be sure to do that before moving forward with this query.
I want to make it clear that these data sources are still being stored in different MongoDB databases in completely different datacenters, but by leveraging MongoDB Atlas Data Lake, we can query all of our databases at once as if all of our data is in a single collection! The following query is only possible using federated search! How cool is that?
// MongoDB Playground
// Select the database to use. Database0 is the default name for a MongoDB Atlas Data Lake database. If you renamed your database, be sure to put in your data lake database name here.
use('Database0');
// We are connecting to `Collection0` since this is the default collection that MongoDB Atlas Data Lake calls your collection. If you renamed it, be sure to put in your data lake collection name here.
db.Collection0.aggregate([
// In the first stage of our aggregation pipeline, we extract and normalize the dataset to only extract zip code data from our dataset.
{
'$project': {
'restaurant_zipcode': '$address.zipcode',
'theater_zipcode': '$location.address.zipcode',
'zipcode': {
'$ifNull': [
'$address.zipcode', '$location.address.zipcode'
]
}
}
},
// In the second stage of our aggregation, we group the data based on the zip code it resides in. We also push each unique restaurant and theater into an array, so we can get a count of the number of each in the next stage.
// We are calculating the `total` number of theaters and restaurants by using the aggregator function on $group. This sums all the documents that share a common zip code.
{
'$group': {
'_id': '$zipcode',
'total': {
'$sum': 1
},
'theaters': {
'$push': '$theater_zipcode'
},
'restaurants': {
'$push': '$restaurant_zipcode'
}
}
},
// In the third stage, we get the size or length of the `theaters` and `restaurants` array from the previous stage. This gives us our totals for each category.
{
'$project': {
'zipcode': '$_id',
'total': '$total',
'total_theaters': {
'$size': '$theaters'
},
'total_restaurants': {
'$size': '$restaurants'
}
}
},
// In our final stage, we sort our data in descending order so that the zip codes with the most number of restaurants and theaters are listed at the top.
{
'$sort': {
'total': -1
}
}
])This outputs the zip codes with the most theaters and restaurants.
[
{
"_id": "10003",
"zipcode": "10003",
"total": 688,
"total_theaters": 2,
"total_restaurants": 686
},
{
"_id": "10019",
"zipcode": "10019",
"total": 676,
"total_theaters": 1,
"total_restaurants": 675
},
{
"_id": "10036",
"zipcode": "10036",
"total": 611,
"total_theaters": 0,
"total_restaurants": 611
},
{
"_id": "10012",
"zipcode": "10012",
"total": 408,
"total_theaters": 1,
"total_restaurants": 407
},
{
"_id": "11354",
"zipcode": "11354",
"total": 379,
"total_theaters": 1,
"total_restaurants": 378
},
{
"_id": "10017",
"zipcode": "10017",
"total": 378,
"total_theaters": 1,
"total_restaurants": 377
}
]Wrap-Up
Congratulations! You just set up an Atlas Data Lake that contains databases being run by different cloud providers. Then, you queried both databases using the MongoDB Aggregation pipeline by leveraging Atlas Data Lake and federated queries. This allows us to more easily run queries on data that is stored in multiple MongoDB database deployments across clusters, data centers, and even in different formats, including S3 blob storage.
If you have questions, please head to our developer community website where the MongoDB engineers and the MongoDB community will help you build your next big idea with MongoDB.
Additional Resources
- Getting Started with MongoDB Atlas Data Lake [Docs]
- AWS re:Invent 2020 Auto-archiving and federated queries
- Tutorial: Federated Queries and $out to AWS S3
Want to check out more of my technical posts?
- How to use MongoDB Client-Side Field Level Encryption (CSFLE) with Node.js
- MongoDB Aggregation Pipeline Queries vs SQL Queries
- An Introduction to IoT (Internet of Toilets)
- How To Use The MongoDB Visual Studio Code Plugin
- Linked Lists and MongoDB: A Gentle Introduction
Follow Joe Karlsson on Social
- Twitter – https://twitter.com/JoeKarlsson1
- TikTok – https://www.tiktok.com/@joekarlsson
- GitHub – https://github.com/JoeKarlsson
- YouTube – https://www.youtube.com/c/JoeKarlsson
- Twitch – https://www.twitch.tv/joe_karlsson
- Medium – https://medium.com/@joekarlsson
- LinkedIn – https://www.linkedin.com/in/joekarlsson/
- Reddit – www.reddit.com/user/joekarlsson
- Instagram – https://www.instagram.com/joekarlsson/