
Let’s face it: Your data can get stale and old quickly. But just because the data isn’t being used as often as it once was doesn’t mean that it’s not still valuable or that it won’t be valuable again in the future. I think this is especially true for data sets like internet of things (IoT) data or user-generated content like comments or posts. (When was the last time you looked at your tweets from 10 years ago?). In this post, we will cover how to manage your data at scale with MongoDB Atlas Online Archive.

This is a real-time view of my IoT time-series data aging.
When managing systems that have massive amounts of data, or systems that are growing, you may find that paying to save this data becomes increasingly more costly every single day. Wouldn’t it be nice if there was a way to manage this data in a way that still allows it to be useable by being easy to query, as well as saving you money and time? Well, today is your lucky day because, with MongoDB Atlas Online Archive, you can do all this and more!
With the Online Archive feature in MongoDB Atlas, you can create a rule to automatically move infrequently accessed data from your live Atlas cluster to MongoDB-managed, read-only cloud object storage. Once your data is archived, you will have a unified view of your Atlas cluster and your Online Archive using a single endpoint..
Note: You can’t write to the Online Archive as it is read-only.
For this demonstration, we will be setting up an Online Archive to automatically archive comments from the sample_mflix.comments sample data set that are older than 10 years. We will then connect to our dataset using a single endpoint and run a query to be sure that we can still access all of our data, whether it’s archived or not.
Prerequisites
- The Online Archive feature is available on M10 and greater clusters that run MongoDB 3.6 or later. So, for this demo, you will need to create a M10 cluster in MongoDB Atlas. Click here for information on setting up a new MongoDB Atlas cluster.
- Ensure that each database has been seeded by loading sample data into our Atlas cluster. I will be using the
sample_mflix.commentsdataset for this demo.
If you haven’t yet set up your free cluster on MongoDB Atlas, now is a great time to do so. You have all the instructions in this blog post.
Configure Online Archive
Atlas archives data based on the criteria you specify in an archiving rule. The criteria can be one of the following:
- A combination of a date and number of days. Atlas archives data when the current date exceeds the date plus the number of days specified in the archiving rule.
- A custom query. Atlas runs the query specified in the archiving rule to select the documents to archive.
In order to configure our Online Archive, first navigate to the Cluster page for your project, click on the name of the cluster you want to configure Online Archive for, and click on the Online Archive tab.
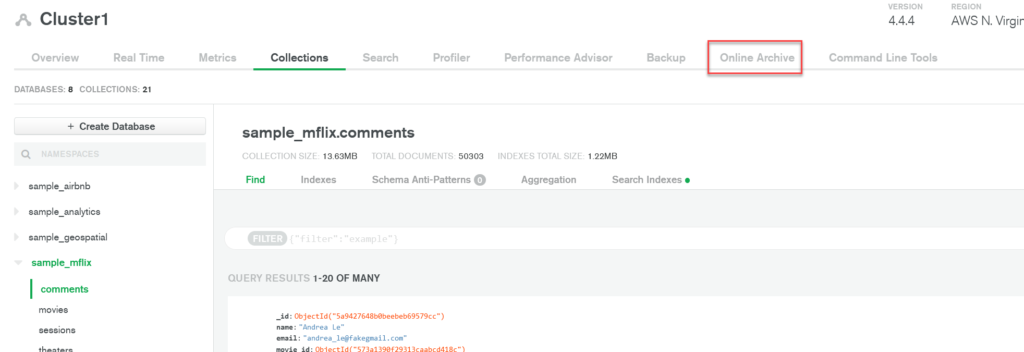
Next, click the Configure Online Archive button the first time and the Add Archive button subsequently to start configuring Online Archive for your collection. Then, you will need to create an Archiving Rule by specifying the collection namespace, which will be sample_mflix.comments for this demo. You will also need to specify the criteria for archiving documents. You can either use a custom query or a date match. For our demo, we will be using a date match and auto-archiving comments that are older than 10 years (365 days * 10 years = 3650 days) old. It should look like this when you are done.
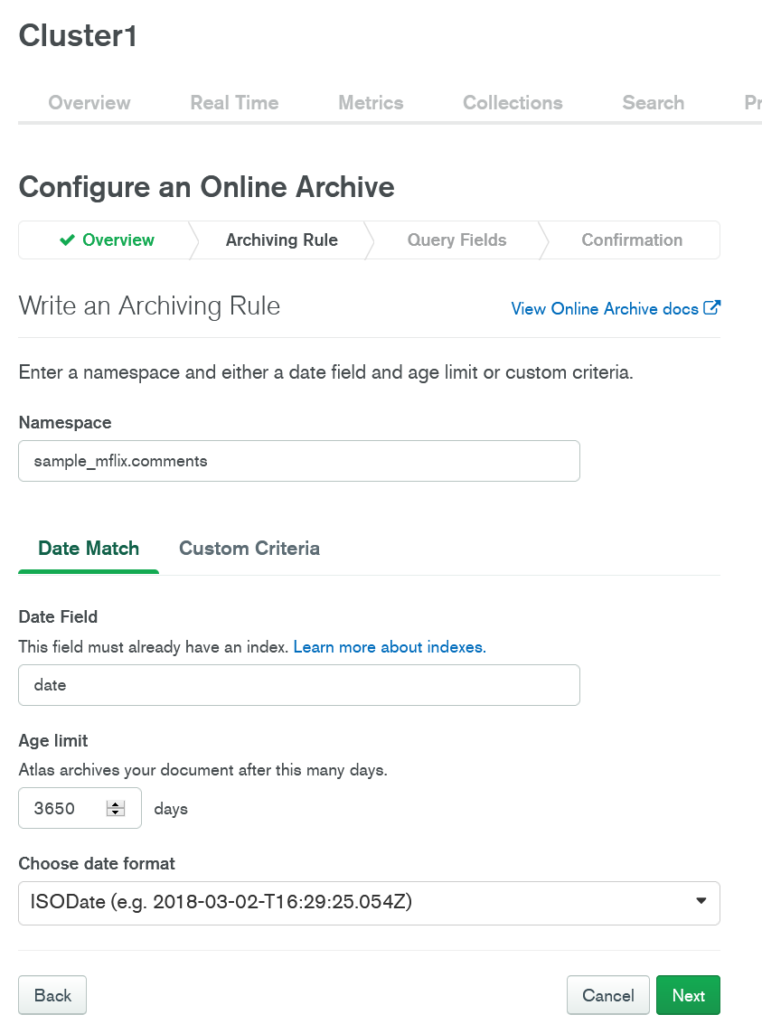
Optionally, you can enter up to two most commonly queried fields from the collection in the Second most commonly queried field and Third most commonly queried field respectively. These will create an index of your archived data so that the performance of your online archive queries is improved. For this demo, we will leave this as is, but if you are using production data, be sure to analyze which queries you will be performing most often on your Online Archive.
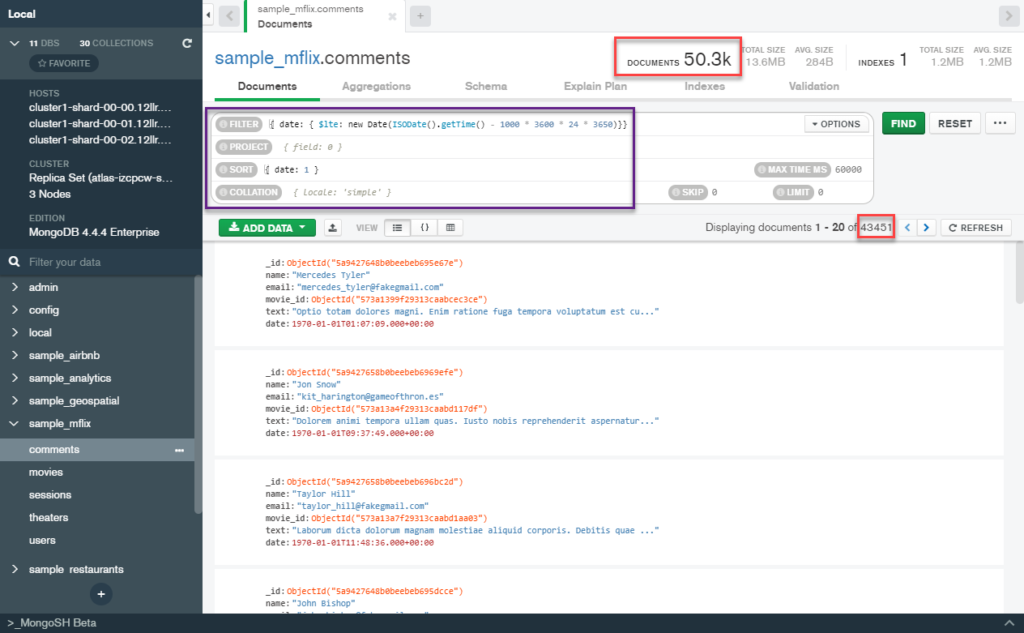
Before enabling the Online Archive, it’s a good idea to run a test to ensure that you are archiving the data that you intended to archive. Atlas provides a query for you to test on the confirmation screen. I am going to connect to my cluster using MongoDB Compass to test this query out, but feel free to connect and run the query using any method you are most comfortable with. The query we are testing here is this.
db.comments.find({
date: { $lte: new Date(ISODate().getTime() - 1000 \* 3600 \* 24 \* 3650)}
})
.sort({ date: 1 })When we run this query against the sample_mflix.comments collection, we find that there is a total of 50.3k documents in this collection, and after running our query to find all of the comments that are older than 10 years old, we find that 43,451 documents would be archived using this rule. It’s a good idea to scan through the documents to check that these comments are in fact older than 10 years old.
So, now that we have confirmed that this is in fact correct and that we do want to enable this Online Archive rule, head back to the Configure an Online Archive page and click Begin Archiving.
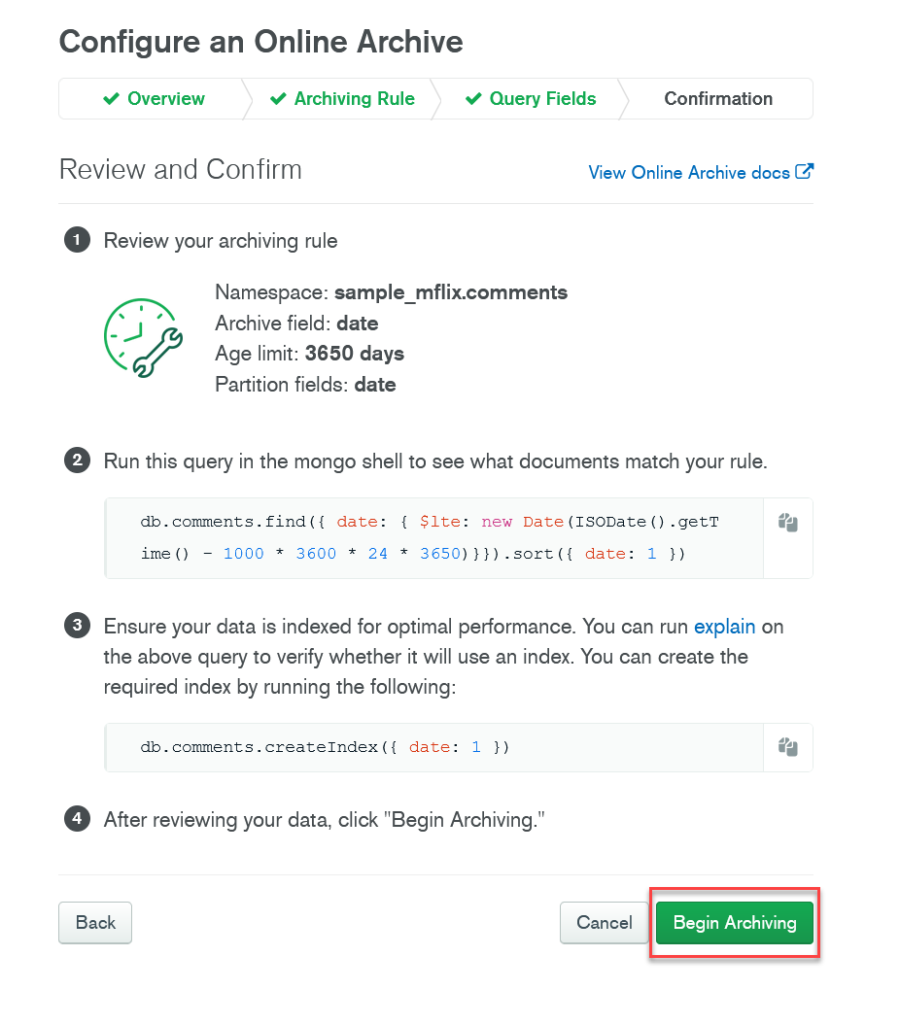
Lastly, verify and confirm your archiving rule, and then your collection should begin archiving your data!

Note: Once your document is queued for archiving, you can no longer edit the document.
How to Access Your Archived Data
Okay, now that your data has been archived, we still want to be able to use this data, right? So, let’s connect to our Online Archive and test that our data is still there and that we are still able to query our archived data, as well as our active data.
First, navigate to the Clusters page for your project on Atlas, and click the Connect button for the cluster you have Online Archive configured for. Choose your connection method. I will be using Compass for this example. Select Connect to Cluster and Online Archive to get the connection string that allows you to federate queries across your cluster and Online Archive.
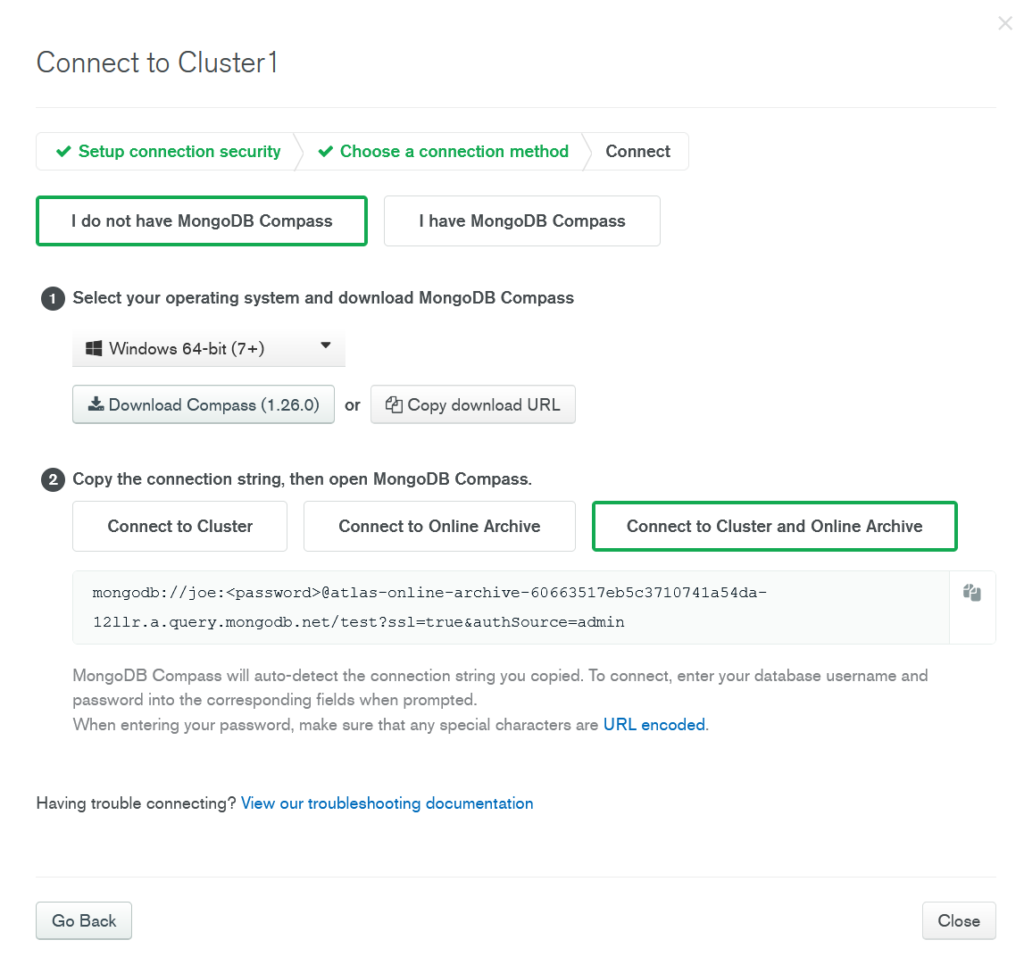
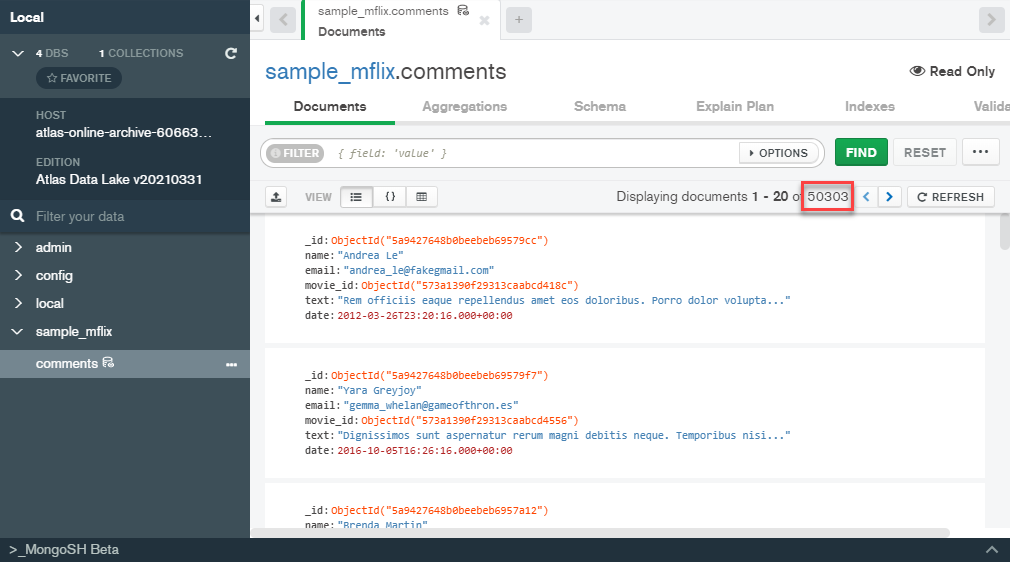
After navigating to the sample_mflix.comments collection, we can see that we have access to all 50.3k documents in this collection, even after archiving our old data! This means that from a development point of view, there are no changes to how we query our data, since we can access archived data and active data all from one single endpoint! How cool is that?
Wrap-Up
There you have it! In this post, we explored how to manage your MongoDB data at scale using MongoDB Atlas Online Archive. We set up an Online Archive so that Atlas automatically archived comments from the sample_mflix.comments dataset that were older than 10 years. We then connected to our dataset and made a query in order to be sure that we were still able to access and query all of our data from a unified endpoint, regardless of whether it was archived or not. This technique of archiving stale data can be a powerful feature for dealing with datasets that are massive and/or growing quickly in order to save you time, money, and development costs as your data demands grow.
If you have questions, please head to our developer community website where the MongoDB engineers and the MongoDB community will help you build your next big idea with MongoDB.
Additional resources:
Want to check out more of my technical posts?
- How to use MongoDB Client-Side Field Level Encryption (CSFLE) with Node.js
- MongoDB Aggregation Pipeline Queries vs SQL Queries
- An Introduction to IoT (Internet of Toilets)
- How To Use The MongoDB Visual Studio Code Plugin
- Linked Lists and MongoDB: A Gentle Introduction
Follow Joe Karlsson on Social
- Twitter – https://twitter.com/JoeKarlsson1
- TikTok – https://www.tiktok.com/@joekarlsson
- GitHub – https://github.com/JoeKarlsson
- YouTube – https://www.youtube.com/c/JoeKarlsson
- Twitch – https://www.twitch.tv/joe_karlsson
- Medium – https://medium.com/@joekarlsson
- LinkedIn – https://www.linkedin.com/in/joekarlsson/
- Reddit – www.reddit.com/user/joekarlsson
- Instagram – https://www.instagram.com/joekarlsson/